RoCE
什么是RoCE?
全称RDMA over Converged Ethernet,RoCE是一种基于以太网的远程直接内存访问(RDMA)技术,旨在通过优化协议栈和硬件卸载,实现高性能、低延迟的数据传输。其核心是通过绕过操作系统内核,减少数据复制和CPU开销,尤其适用于AI训练、超算和分布式存储等场景。
从 2010 年开始,RMDA 开始引起越来越多的关注,当时IBTA发布了第一个在融合以太网 (RoCE) 上运行 RMDA 的规范。然而,最初的规范将 RoCE 部署限制在单个第 2 层域,因为 RoCE 封装帧没有路由功能。2014 年,IBTA 发布了 RoCEv2,它更新了最初的 RoCE 规范以支持跨第 3 层网络的路由,使其更适合超大规模数据中心网络和企业数据中心等。
RoCEv1
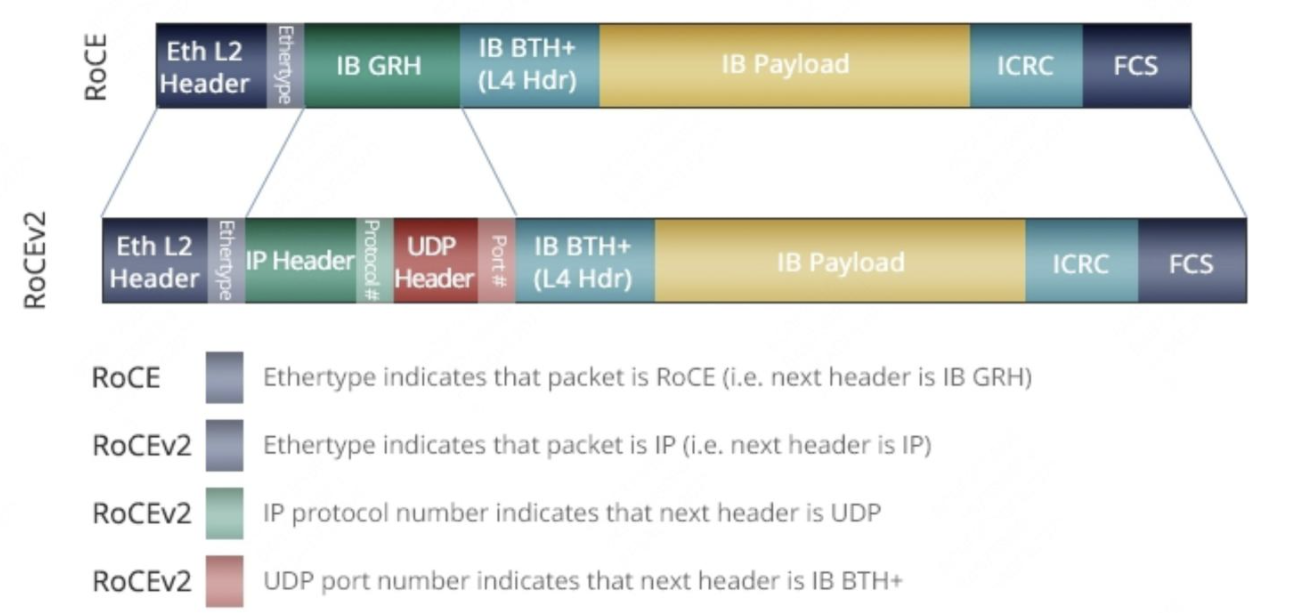
2010年4月,IBTA发布了RoCE,此标准是作为Infiniband Architecture Specification的附加件发布的,所以也称为IBoE(InfiniBand over Ethernet)。这时的RoCE标准是在以太链路层之上用IB网络层代替了TCP/IP网络层,所以不支持IP路由功能。RoCE V1协议在以太层的typeID是0x8915。
在RoCE中,infiniband的链路层协议头被去掉,用来表示地址的GUID被转换成以太网的MAC。Infiniband依赖于无损的物理传输,RoCE也同样依赖于无损的以太传输,这一要求会给以太网的部署带来了成本和管理上的开销。
以太网的无损传输必须依靠L2的QoS支持,比如PFC(Priority Flow Control),接收端在buffer池超过阈值时会向发送方发出pause帧,发送方MAC层在收到pause帧后,自动降低发送速率。这一要求,意味着整个传输环节上的所有节点包括end、switch、router,都必须全部支持L2 QoS,否则链路上的PFC就不能在两端发挥有效作用。
RoCEv2
由于RoCEv1的数据帧不带IP头部,所以只能在L2子网内通信。为了解决此问题,IBTA于2014年提出了RoCE V2,RoCEv2扩展了RoCEv1,将GRH(Global Routing Header)换成UDP header + IP header,扩展后的帧结构如下图所示。
针对RoCE v1和RoCE v2,以下两点值得注意:
- RoCE v1(Layer 2)运作在Ethernet Link Layer(Layer 2)所以Ethertype 0x8915,所以正常的Frame大小为1500 bytes,而Jumbo Frame则是9000 bytes。
- RoCE v2(Layer 3)运作在UDP/IPv4或UDP/IPv6之上(Layer 3),采用UDP Port 4791进行传输。因为 RoCE v2的封包是在 Layer 3上可进行路由,所以有时又会称为Routable RoCE或简称RRoCE。
RoCEv2的普及性
生态成熟度:国内云计算与AI企业(如阿里云、腾讯云、华为云)普遍采用RoCEv2,因其兼容现有以太网架构且性价比高。例如,华为鲲鹏920芯片已支持100Gbps RoCE,并在数据中心部署中实现端到端延迟5-10μs。
应用场景:大规模AI训练(如千卡级集群)和分布式存储(如EMC Isilon)通过RoCEv2优化通信效率,实际带宽利用率达90%以上(400G以太网实测360Gbps)。
对比InfiniBand
| 维度 | RoCEv2 | InfiniBand |
|---|---|---|
| 协议栈 | 基于UDP/IP的以太网扩展 | 专用协议栈(物理层到传输层独立设计) |
| 部署成本 | 利用现有以太网设备,成本低 | 需专用交换机和网卡,成本高 |
| 扩展性 | 支持三层路由,扩展性强 | 依赖子网管理器(SM),集中式管理 |
| 性能 | 延迟略高(微秒级),吞吐量接近IB | 超低延迟(纳秒级),吞吐量更高 |
| 适用场景 | 通用数据中心、云计算、AI训练 | 超算中心、极致性能要求的HPC环境 |